Welcome to my blog!
Mandil Karki
Categories
All
(4)
LLMs
(1)
Mistral
(1)
Mixture of Experts
(1)
data preparation
(1)
deep learning
(2)
machine learning
(3)
transformers
(2)
word embeddings
(2)
word vectors
(2)
Comprehensive Understanding of Mistral Model
Mixture of Experts
Mistral
LLMs
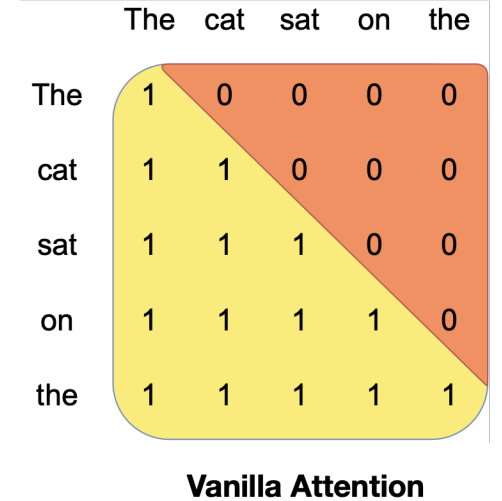
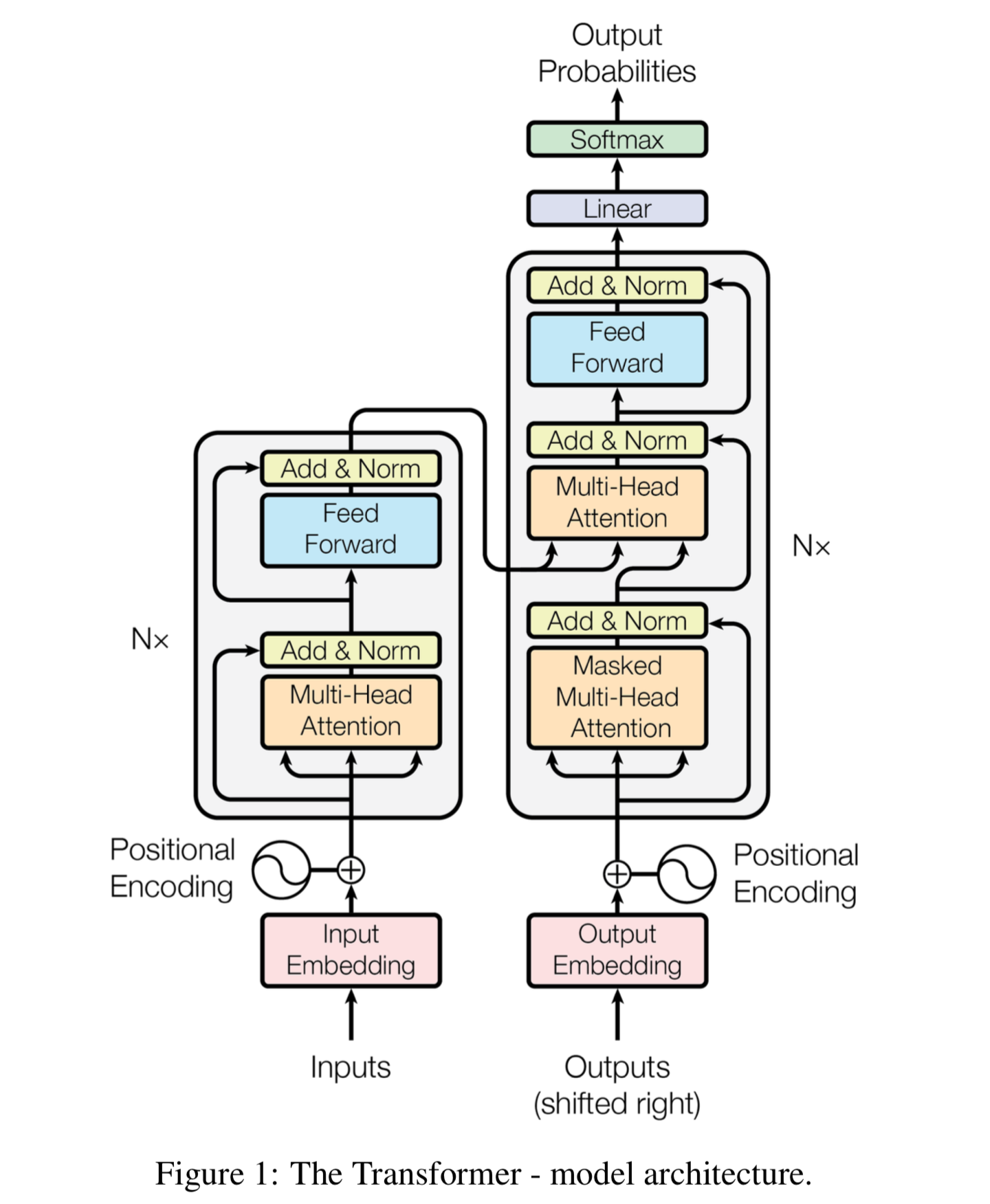
Attention mechanism is a key component in Transformer models. It allows the model to focus on different parts of the input sequence and derive the relationship between…
Mar 11, 2024
Mandil Karki
Self-Attention & Transformer
machine learning
word vectors
word embeddings
transformers
deep learning
The necessities for a self-attention model are as follows:
Oct 23, 2022
Mandil Karki
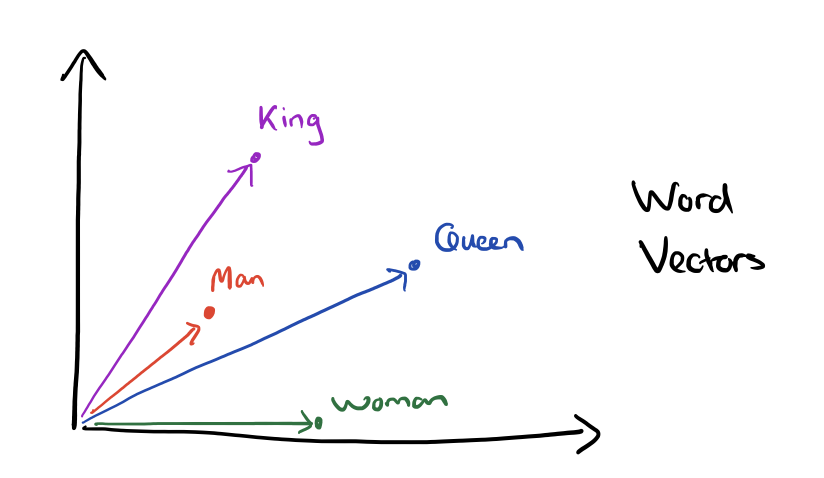
Word Vectors
machine learning
word vectors
word embeddings
transformers
deep learning
Word vectors are also called
word embeddings
or neural word representations because these whole bunch of words are represented in a high dimensional vector space and they…
Oct 15, 2022
Mandil Karki
Data Fundamentals
machine learning
data preparation
Outliers are examples that look dissimilar to the majority of examples from the dataset. Dissimilarity is measured by some distance metric, such as
Euclidean distance.
Deleti…
Mar 15, 2022
Mandil Karki
No matching items